
31 May 2016
GeoDeepDive: Bringing dark data to light
Posted by Nanci Bompey
By Leandra Marshall
This is part of a new series of posts that highlight the importance of Earth and space science data and its contributions to society. Posts in this series showcase data facilities and data scientists; explain how Earth and space science data is collected, managed and used; explore what this data tells us about the planet; and delve into the challenges and issues involved in managing and using data. This series is intended to demystify Earth and space science data, and share how this data shapes our understanding of the world.
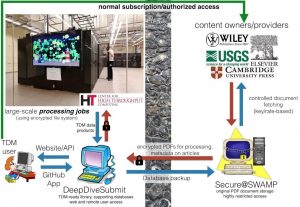
A schematic overview of GeoDeepDive’s infrastructure.
Credit: GeoDeepDive
Data represent the lifeblood of the scientific circulatory system. For example, paleontologists constantly seek new ways to find, prepare and analyze fossil specimens to better understand Earth’s biological past. The research of thousands of paleontologists toiling over many lifetimes yields an evolving quantitative summary of the history of life; a summary that is enriched over time.
Paleontologists, and most other geoscientists and scientists, read published literature and synthesize information to address scientific questions. Paleontologists have tried to create paleontology data synthesis manually by building resources like the Paleobiology Database, but the data entry process is arduous and constantly incomplete because new research is always being published. While the internet provides easier access to documents, it does not help manage the millions of publications that are accessible online. Global scientific literature is published so quickly that it is impossible for any one scientist to keep up. This is where GeoDeepDive, an National Science Foundation-funded EarthCube project, can help.
GeoDeepDive is a “digital library of the future,” and consists of a cyberinfrastructure to find and manage documents from content providers (such as various digital literature databases) through a computing application that can “read” and repeatedly add information to each document. GeoDeepDive is able to prepare documents so they can be read by machines and used to aid large-scale text and data mining activities. “For me, personally, such an infrastructure promises to lower the barrier to generating the new synthetic results that are necessary to address some pretty important questions in Earth systems science. Many examples of such synthetic results involve compiling data that are ultimately field and sample derived, such as fossil and mineral occurrences, geochemical measurements, and the like,” says Shanan Peters, one of the principal investigators of GeoDeepDive.
In the short term, the project’s infrastructure allows geoscientists to find and extract data from literature efficiently with far less effort. GeoDeepDive also adds new documents to its user library as they are published. The system is intelligent enough to recognize new documents as potentially relevant to a specific project and direct those documents to data extraction applications. In the long term, GeoDeepDive will not only store information and allow easy access for scientists, it will also use high throughput computing (HPC) systems to read, analyze and convey information, allowing scientific questions far beyond “where is this research paper?”
GeoDeepDive is the beginning of a new type of library, ultimately transforming the definition of what a library is and does. This system will distill thousands of pages of research to a practical summary of relevant information. “I think we really could be taking one small step towards the library of the future, where there are not static shelves with books, or webpages with links, where one goes to look for something that must then be retrieved and read to obtain information,” says Peters.
There are already a few examples of success. Undergraduate student Julia Wilcots used the GeoDeepDive system during her research on stromatolite distribution over space and time, which resulted in a poster at the 2015 Geological Society of America conference. Elements of the GeoDeepDive infrastructure are utilized in Macrostrat, a geologic database. Peters says that the feedback on GeoDeepDive is encouraging. “The publishers with whom we have been working have been very positive and intrigued about where we are going, particularly given our strong desire to come up with new, much more complete, ‘knowledge citation’ methods,” says Peters, who said that the involvement of University of Wisconsin-Madison library system in the project could be helpful to that end.
EarthCube’s GeoDeepDive promises to be an important innovation for geosciences and data science. Peters encourages interested geoscientists to get involved. “We are just getting to the point where we can start doing interesting things with collaborators. It would be great if geoscientists contacted us to start a collaboration that will help them do science while at the same time helping us to learn and grow!”
For more information on GeoDeepDive, visit the project’s Youtube video, their website and the DeepDive tool. Watch GeoDeepDive’s webinar Friday, June 3, at 2 p.m. EDT (11 am PDT): Shanan Peters, John Czaplewski, Miron Livny and Ian Ross from the University of Wisconsin: “GeoDeepDive: A digital library and infrastructure to support text and data mining.”
—Leandra Marshall is a Project Coordinator at the Earthcube National Office.







