
28 July 2016
NOAA Makes Decision on New Global Weather Model. Controversy Likely.
Posted by Dan Satterfield
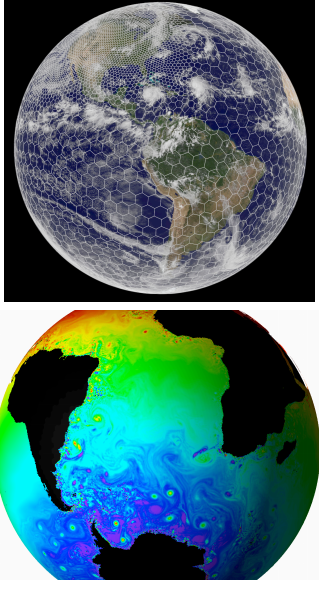
More on MPAS from this pdf. Click image.
NOAA has decided on the nuts and bolts of a new, next generation, weather model that will replace the present Global Forecast System (GFS model), and the choice is sure to spark some controversy. The choice boiled down to a system called MPAS vs FV3. Many meteorologists were rooting for MPAS, which was developed by NCAR, while NOAA was leaning toward the FV3 which was a project of the GFDL Lab.
Dr. Cliff Mass (at the Univ. of Washington) has written several blog posts about how we have fallen behind in numerical weather modelling, and has been championing the MPAS system as the much better way forward. It looks like this will not happen, based on news I just heard about tonight. NOAA chose the FV3 today, instead of MPAS (The video above shows the FV3 in action) and I am anxious to hear the debate that will soon ensue.
There are two sides to this issue, and smart people have different opinions on both sides, and NOAA’s press release is here. I’ve asked Cliff Mass for a comment, and will update this post when new info arrives. NOAA folks, and others, who favor the FV3 core, I would love to share your views as well.
We definitely need a new global model. The ECMWF model, run in the UK near London, is clearly superior, but NOAA’s high-resolution, short-range HRRR model is state of the art for very short-range forecasting, and it’s about to be upgraded, and run out beyond the current 15 hours. The ECMWF folks do one very good global model. Charles Emerson Winchester (M*A*S*H) said it best at 2:05 in this video: https://www.youtube.com/watch?v=75Ubs8i8fJU. While NOAA runs regional/global/air pollution, and ocean models, so things are different here.
So, there you have it. More on this soon, and while I thought Cliff Mass made a very good case for MPAS, I’m not taking sides..yet. Actually, I say we run both!
 Dan Satterfield has worked as an on air meteorologist for 32 years in Oklahoma, Florida and Alabama. Forecasting weather is Dan's job, but all of Earth Science is his passion. This journal is where Dan writes about things he has too little time for on air. Dan blogs about peer-reviewed Earth science for Junior High level audiences and up.
Dan Satterfield has worked as an on air meteorologist for 32 years in Oklahoma, Florida and Alabama. Forecasting weather is Dan's job, but all of Earth Science is his passion. This journal is where Dan writes about things he has too little time for on air. Dan blogs about peer-reviewed Earth science for Junior High level audiences and up.
This is interesting. How does one go about comparing two systems as complicated as two weather models? The naive way is finding the one that has the smallest log-likelihood difference on datasets, perhaps penalized, but what set of datasets are going to be sufficiently representative? It almost seems like you want to do ensembles of realizations from actual data and test them on that … And is smallest log-likelihood the best measure? Maybe something like smallest maximum deviation is the best, since it is important that a forecast in any locale not be off by more than a given amount. Are there papers that discuss this?
I am not an expert on NWP modeling, but Cliff Mass at UW has a great piece here about it. He was pushing for the other dynamical core (NCAR version). It has to do with the grid scaling, and run time differences between the two dynamical cores. He has a good detailed post on the differences here- http://cliffmass.blogspot.com/2016/07/the-national-weather-service-moves-to.html
Both sides have a point, but I think Cliff Mass has a real point.
(Sorry largest log-likelihood in the above … I’m so used to using minus log-likelihood I forgot to flip.)